Agentic AI and Identity Governance

Quarterly access reviews don't work when identities need credentials for 90 seconds. Agentic AI provisions access dynamically, operates autonomously, and executes at machine speed.
And worse, traditional identity and access management (IAM) systems can't keep up. By the time access reviews complete, agents have already provisioned, used, and revoked credentials thousands of times.
This speed mismatch creates an 'assumption gap' for organizations already deploying agentic AI.
Most IAM models assume identities are stable, and access can be granted ahead of time. That's why role-based access control (RBAC) works for humans and traditional systems.
But agentic AI doesn't operate that way. Access needs change from one action to the next, and decisions are made in real time.
Yet, organizations still apply static controls to dynamic identities. OAuth tokens remain valid for hours when agents only need access for minutes. Permissions are pre-assigned broadly to avoid breaking workflows.
That mismatch between how agents operate and how access is governed is where risk compounds.
Closing that gap requires understanding what makes agent identities different, what risks they create, and what governance approaches actually work for autonomous systems.
How AI Agents Differ From Human and Machine Identities#
AI agents change the identity conversation because they do not behave like traditional users or machine accounts managed through conventional IGA systems.
- A human identity usually maps to a known person with a persistent role, predictable access needs, and clear accountability.
- A machine identity, such as a service account, API key, or bot, is typically created for a fixed purpose and follows predefined instructions.
- An AI agent sits in a different category. It is still a non-human identity, but it is one that can interpret context, make decisions, choose actions, and interact with systems in ways that are far less static.
Let's break down the differences clearly:
Dynamic and Ephemeral Identity Lifecycles#
Human identities follow predictable patterns. Employees join the organization, receive credentials during onboarding, accumulate permissions over months or years, and eventually leave when employment ends.
Their identity lifecycle measures in months to years, with permissions changing occasionally through formal access requests or role changes.
Traditional machine identities aren't much different in practice. A service account gets created for an application, receives the permissions that application needs, and exists for a while. Sometimes, longer than necessary—until someone remembers to decommission it.
But still, these identities are long-lived and relatively stable.
AI agents operate on completely different timescales. An agent spins up to execute a specific task—e.g., analyze a dataset, generate a report—and exists only as long as that task requires.
Task completion might take 90 seconds or 90 minutes, but once finished, the agent and its associated identity dissolve.
However, the credentials provisioned for that agent doesn't expire with it. Instead, they persist indefinitely like traditional service accounts.
This 'ephemerality' creates identity governance challenges traditional systems weren't built to handle. Identity platforms designed to manage thousands of users with years-long lifecycles struggle when managing thousands of agents with minute-long lifecycles.
Access review processes assuming identities exist long enough to review become meaningless when identities appear and disappear between review cycles.
Autonomous Decision-Making Without Human Triggers#
Traditional identities (both human and machine) operate reactively.
Here's an example:
- A human user decides they need access to a system and submits a request.
- An application attempts to connect to a database and uses pre-configured credentials.
- The decision to request or use access traces back to human intent, whether directly (user requesting access) or indirectly (developer configuring application credentials).
However, AI agents make access decisions autonomously. An agent assigned to "reduce customer churn" might autonomously determine it needs to analyze customer support tickets, access CRM data, query product usage analytics, and retrieve billing history.
No human explicitly told the agent to access those specific systems. The agent evaluated its objective, formulated a plan requiring access to multiple data sources, and proactively requested the credentials needed to execute that plan.
This autonomy changes the fundamentals of identity governance. When humans request access, governance systems can evaluate whether the request is appropriate based on the person's role, their justification, and their manager's approval.
When agents request access, governance systems now need to assess agent behavior in real time, ensuring every request aligns with policy, business context, and acceptable risk management thresholds.
The Four-Layer Architecture#
AI agents also differ because they tend to operate through a layered internal structure that makes them more adaptive than standard machine identities.
This structure is often best understood through four functional layers: perception, planning, action, and memory. Together, these layers explain why agentic identity is more complex than identity for static bots or scripts.
Perception#
This is how the agent reads signals from its environment. This could include user input, system events, application state, telemetry, documents, API responses, or workflow context.
A traditional machine identity usually does not meaningfully interpret its environment beyond receiving an input and executing a preset function. An agent, by contrast, can ingest multiple signals and use them to shape what it does next.
Planning#
This is the reasoning layer. Here, the agent interprets its goal, evaluates available options, and decides how to proceed. This is where it may determine that it needs access to a file store, a ticketing system, a code repository, or an internal application in order to complete a task.
Action#
This is where the agent executes. It may call APIs, retrieve data, create records, modify workflows, or trigger other systems. This is the layer most comparable to what service accounts already do. The only difference is that the actions are often selected dynamically rather than hard-coded in advance.
Memory#
This allows the agent to retain context across interactions or sessions. That context may include prior instructions, earlier decisions, workflow state, or learned preferences.
Human users also retain memory, of course, but in identity governance terms, this means the agent may carry forward operational context that influences future access decisions or actions. Traditional machine identities usually do not have this kind of evolving context layer.
These layers also introduce new cybersecurity considerations, where access is no longer tied to fixed roles but to dynamic context across perception, planning, and execution.
Varying Levels of Autonomy#
Not all AI agents operate at the same level of independence, and that variation is another reason they differ from both human and machine identities.
Some are relatively narrow and reactive. Others are capable of long-range reasoning and coordination. Identity governance has to account for that range rather than treating all agents as if they pose the same level of risk.
At the lower end are reactive agents. These respond quickly to triggers or events.
For example, an agent may detect an incoming request, check a condition, and perform a limited action. These agents are more dynamic than basic bots, but their behavior is still fairly bounded. Their access patterns may be easier to predict, though they still need tight controls because they can act quickly and repeatedly.
A step above are deliberative agents. These can work through more complex objectives, evaluate multiple paths, and sequence tasks over time.
This increases governance complexity because the access they request may change as their plan evolves. They may need multiple systems, different permissions at different stages, and the ability to adapt when conditions shift.
At the most complex end are multi-agent systems, where several AI agents interact with one another to complete a broader goal. One agent may gather information, another may analyze it, and another may execute a task.
In some environments, agents may even negotiate, delegate, or coordinate responsibilities across systems. This creates a much more complicated identity model because the organization is no longer governing one non-human identity in isolation. It is governing an ecosystem of interacting non-human actors, each with its own permissions, context, and role in the workflow.
Why this difference is important
The core issue is that AI agents combine traits from both humans and machines without fitting cleanly into either category.
Like machines, they are non-human and can act at scale. Like humans, they can interpret context, adapt to changing conditions, and make decisions that influence what happens next.
But unlike both, they may appear and disappear quickly, operate autonomously, and collaborate across systems with very little friction.
When Quarterly Access Reviews Don't Work for 90-Second Identities#
How Instacart is using AI to achieve zero standing privileges →
Limitations of Traditional Identity Frameworks#
OAuth and SAML Shortcomings#
Protocols like OAuth and SAML help to manage access between users, applications, and services in relatively stable environments. They work well when access needs are predictable and sessions can be clearly defined.
OAuth, for example, relies heavily on access tokens that are often valid for a fixed duration. Once issued, that token grants access until it expires or is revoked.
The problem with AI agents is that their access needs are not fixed. An agent may require elevated access for a single API call and then immediately no longer need it. A long-lived token in this context becomes a liability. It creates a window where the agent has more access than necessary for longer than necessary.
SAML, on the other hand, is built around session-based authentication using static assertions. It assumes a user logs in, establishes a session, and maintains that identity throughout the interaction.
This model struggles with AI agents because there is no meaningful "session" in the traditional sense. Agents may spin up, execute multiple micro-actions across systems, and terminate quickly. Trying to map that behavior to a static session model introduces friction and blind spots.
The core issue is that both OAuth and SAML are 'transaction-based', while AI agents operate in a continuous, context-driven flow. They lack the ability to adjust privileges in real time based on what the agent is doing at that exact moment.
The Failure of Role-Based Access Control (RBAC)#
Role-Based Access Control (RBAC) is built on the idea that users can be grouped into roles, and each role is assigned a fixed set of permissions. This works reasonably well when job functions are stable and access needs don't change frequently.
AI agents don't fit into static roles. An agent's access requirements are tied to the task it is performing, not to a predefined role.
In one moment, it may need read-only access to a knowledge base. In the next, it may need to write data to a system, trigger a workflow, or query a different service entirely. Assigning all possible permissions upfront violates the principle of least privilege, creating excessive entitlements that expand the blast radius if an agent is compromised.
RBAC also lacks the ability to factor in context. It does not evaluate why access is being requested, what the agent is trying to achieve, or whether the request aligns with policy at that specific point in time. It simply checks whether the role has permission.
For AI agents, this is insufficient. What's needed is fine-grained, context-aware access control that can evaluate intent, scope access to a single action, and revoke it immediately after use. RBAC, by design, cannot operate at that level of precision or speed.
Point-in-Time Trust Assumptions#
Traditional identity frameworks rely on a simple model— 'authenticate once, trust for the duration of the session.'
A user logs in, passes authentication, and is then allowed to operate under that identity until the session expires. The system assumes that the user's intent and behavior remain consistent throughout that session.
This assumption does not hold for AI agents. An agent's behavior can evolve within seconds. It may start with a legitimate task, then encounter new inputs, adjust its plan, and request access to additional systems or data. The risk profile changes dynamically, but traditional frameworks have no mechanism to reassess trust in real time.
This creates a gap where an agent can be authenticated correctly at the start, but still perform risky or unauthorized actions later in the same execution flow. There is no continuous validation of intent, no re-evaluation of permissions, and no adaptive enforcement based on changing context.
For AI agents, identity governance needs to move from point-in-time authentication to continuous verification. This is where observability becomes critical. With visibility into every request, decision, and action, security teams can validate whether access aligns with policy or detect deviations early enough to respond.
Core Security Risks Posed by AI Agents#
AI agents create a different class of security risk than ordinary chatbots because they do more than generate text.
They can hold context across steps, call tools, access data stores, trigger workflows, and take action in external systems. That is why the attack surface grows so quickly as organizations move from basic copilots to agentic systems.
This introduces a set of risks that traditional identity and security controls are not designed to handle.
Overprivilege and Excessive Autonomy#
One of the biggest risks with AI agents is that teams often give them broad, persistent permissions just to make workflows run smoothly.
An agent that handles approvals, SaaS administration, ticket triage, or code changes may be granted access to email, calendars, cloud consoles, internal docs, source control, and deployment tools at the same time.
That makes the agent useful, but it also turns it into a high-value identity with more reach than most human users should ever have.
In many cases, these permissions accumulate over time without proper deprovisioning, leaving behind dormant identities and unused entitlements that attackers can exploit later.
The risk is further amplified by tool use. OpenAI's Operator system card warns that agent-style systems introduce risks like prompt injection from third-party websites, unintended actions, and hard-to-reverse mistakes *.
A practical example is an AI agent that can both read internal documents and execute administrative actions in a SaaS stack. If it is overprivileged, a single manipulated step can lead to data access, permission changes, or destructive actions that were never intended by the user.
Recommended → Three Properties Identity Must Have in the Agentic Era
Credential Misuse and Token Exposure#
AI agents depend heavily on non-human credentials such as API keys, OAuth tokens, service-account secrets, session cookies, and connector authorizations.
If those credentials are stolen, the attacker inherits whatever the agent can already do across its connected systems. That includes the ability to execute tasks, access data, and interact with multiple systems autonomously.
What makes it worse is that, unlike a human account, where suspicious activity may be noticed or limited by behavior, an agent's activity can appear normal because it is already automated. This makes credential compromise harder to detect and more impactful when it happens.
For example, in a report by GitGuardian, 23,770,171 new hardcoded secrets were found in public GitHub commits in 2024, and 70% of the secrets leaked in 2022 were still valid in 2025 *.
A newer report found 28,649,024 new secrets leaked in public GitHub commits in 2025, with AI-assisted commits showing roughly double the leak rate of the GitHub-wide baseline. The same research found 1,275,105 leaked AI-service secrets in 2025, an 81% year-over-year increase *.
In a nutshell, as LLMs and agentic systems become more embedded into workflows, a single compromised credential can unlock access across multiple tools, data sources, and execution paths.
Lateral Movement in Multi-Agent Ecosystems#
As organizations adopt more complex agentic architectures, they stop running a single assistant and start running systems of agents.
One agent gathers context, another queries internal data, another calls business tools, and another takes action.
That architecture is powerful, but it also creates new trust paths that attackers can exploit. When that trust is abused, the attacker may not need to exploit a software vulnerability in the classic sense. They can exploit the workflow itself. That is a much harder problem to detect if security teams are only watching endpoints and identity logs in isolation.
And because these interactions are designed to be seamless and automated, they can be difficult to intercept once initiated.
Accountability and Black Box Operations#
One of the most complex risks with AI agents is the lack of clear accountability. When an agent executes a chain of actions (especially across multiple systems) it becomes difficult to trace exactly how a specific outcome was reached.
With traditional systems, there's a clear attribution showing a user performed an action at a specific time.
But with AI agents, decisions are often distributed across perception, planning, and execution layers. Inputs change, context evolves, and actions may be taken based on intermediate reasoning steps that are not fully visible.
Without granular logging covering prompts, decisions, access requests, and executed actions, organizations are left with a black box.
As such, when something goes wrong, whether it's data exposure, incorrect execution, or policy violation, it becomes difficult to determine what happened, why it happened, and who or what is responsible.
Note: The core pattern across all four risks is the same. AI agents concentrate privilege, credentials, workflow trust, and decision-making opacity into one operating layer.
As AI adoption rises, security teams need to treat agents as high-risk non-human identities rather than as ordinary software features.
Get full visibility into AI agents, service accounts, API keys, secrets, and more across your environment.
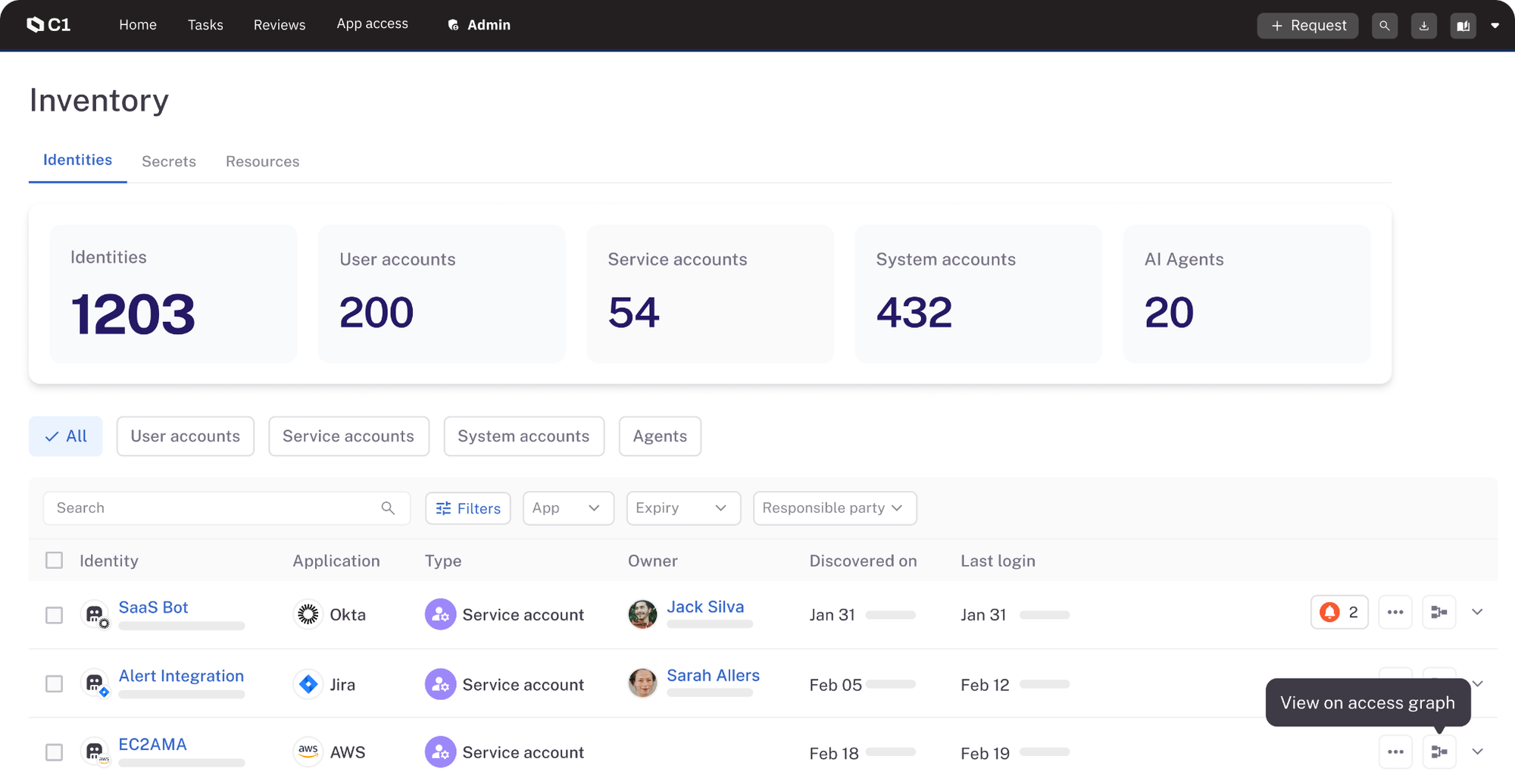
No more unknowns—view and manage all your identities in one platform.
Compliance and Regulatory Considerations for Agentic AI#
AI-specific regulations are transitioning from proposed frameworks to enforceable law with real penalties for non-compliance.
Organizations deploying agentic AI must demonstrate documented, auditable control over autonomous systems.
Compliance requirements designed for human decision-making now apply to AI agents making autonomous decisions, creating governance obligations many organizations aren't prepared to meet.
Navigating the EU AI Act#
The EU AI Act categorizes AI systems by risk level and imposes mandatory requirements proportional to that risk.
Many agentic AI deployments fall into the "high-risk" category due to the systems they interact with, the decisions they make, or the data they process.
One of its main expectations is effective human oversight—ensuring that AI systems do not operate entirely unchecked in critical scenarios.
For agentic AI, this means designing workflows where human intervention is not optional. High-impact actions such as modifying financial records, accessing sensitive datasets, or executing operational changes, should include Human-in-the-Loop (HITL) checkpoints.
These are control points where a human can review, approve, or override the agent's decision before it is executed.
The challenge is balancing control with efficiency. Too much friction slows down automation, but too little oversight creates compliance risk. Strong AI governance frameworks are essential here, ensuring that human oversight, policy enforcement, and automation coexist without slowing down critical workflows.
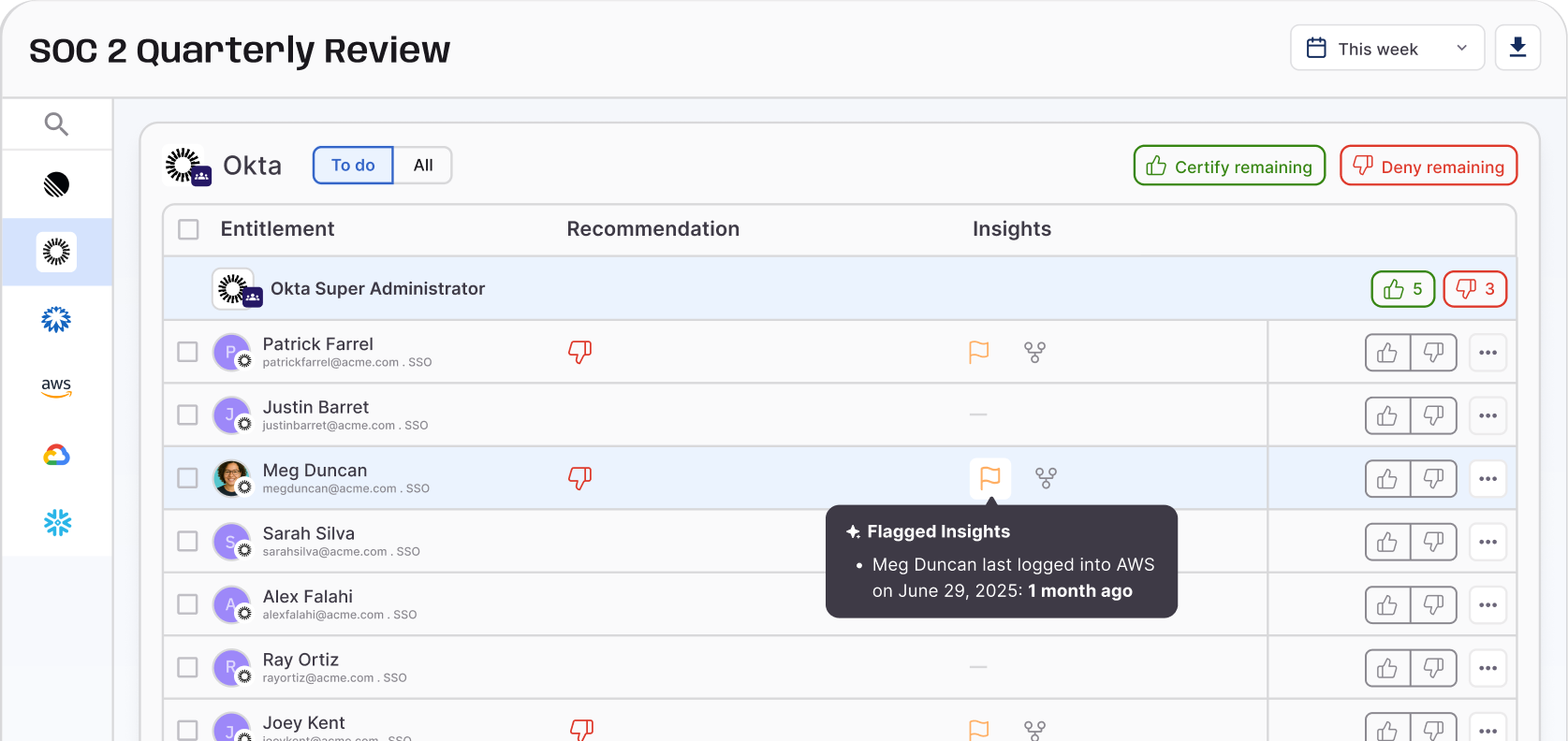
Maintaining Transparent Audit Trails#
Regulatory expectations around explainability are increasing, and agentic systems make this harder to achieve.
It is not enough to log that an API call was made—organizations must be able to explain why it was made, what triggered it, and under whose authority it was executed. This requires translating low-level technical activity into human-readable audit trails.
For example, instead of logging "Agent A called API X," the system should be able to show: the originating request, the reasoning path, the permissions used, and the identity that authorized those permissions.
Without this level of traceability, compliance breaks down quickly. During an audit or incident investigation, organizations must be able to reconstruct the full chain of events—from initial input to final action.
Risk-Based Deployment#
A key principle in modern AI regulation is that not all use cases carry the same level of risk. As such, Agentic AI should not be deployed with full autonomy from day one. Instead, organizations are expected to adopt a progressive, risk-based approach.
This typically starts with controlled environments—e.g., sandbox or staging systems—where agent behavior can be tested, observed, and validated without impacting production systems.
Effective sandboxes for agentic AI include:
- Synthetic data environments: Realistic but fabricated data enabling agents to perform analysis without accessing sensitive information.
- Mock system integrations: Simulated APIs and services allowing agents to practice coordinating with systems without affecting real infrastructure.
- Adversarial testing scenarios: Intentional attempts to manipulate agents through prompt injection, malicious inputs, or edge cases.
- Failure condition simulation: Testing how agents behave when systems are unavailable, data is corrupted, or operations fail.
- Permission boundary testing: Verifying agents respect access controls and don't attempt to escalate privileges inappropriately.
From here, autonomy is introduced gradually.
Low-risk tasks, such as internal data summarization or non-sensitive workflow automation, can be automated earlier. Higher-risk actions—especially those involving sensitive data, financial operations, or system changes—should require stricter controls, including limited permissions, monitoring, and human approval layers.
Over time, as the agent demonstrates reliability, permissions can be expanded. But always within defined boundaries and with continuous evaluation.
Recommended → 13 IGA Best Practices for Modern Identity Security
Data Protection and Privacy Obligations#
Agentic AI often interacts with large volumes of sensitive data, which brings it directly under regulations like GDPR and similar data protection laws.
Organizations must ensure that agents only access data necessary for their task (data minimization), that sensitive data is protected in transit and at rest, and that any processing aligns with lawful use requirements.
This becomes more complex when agents dynamically decide what data to access, making strong access controls and real-time validation essential.
Additionally, organizations need to account for how data is used within prompts, logs, and outputs. Even temporary exposure such as pasting sensitive data into an agent prompt can create compliance risk if not properly controlled.

How DigitalOcean reduced identity security risk by automating user access reviews →
Best Practices for Governing AI Agents#
Implement Ephemeral Authentication#
Persistent credentials are one of the biggest risks in agentic environments. That's why AI agents don't need long-lived access—they need precise, short-lived permissions tied to a specific task.
Ephemeral authentication replaces static API keys and long-lived tokens with temporary, context-aware credentials.
These credentials are generated at the moment of need, scoped to a single action or workflow, and expire immediately after use. It also strengthens overall security posture, ensuring that no identity retains access longer than necessary.
Enforce Just-in-Time (JIT) Access#
Pre-assigning broad permissions to agents creates unnecessary risk. Instead, access should be granted only when requested and only for the duration required.
Just-in-time (JIT) access ensures that agents do not carry standing privileges. When an agent needs to perform an action, it must request access, which is then evaluated in real time against defined policies. Once the task is completed, that access is revoked automatically.
This approach also aligns access with intent. Rather than assuming what an agent might need, the system evaluates what it actually needs in the moment, reducing overprivilege and limiting the impact of misuse.
Adopt Attribute-Based Access Control (ABAC)#
Static access models like RBAC cannot handle the dynamic nature of AI agents. Instead, access decisions should be based on real-time attributes.
Attribute-Based Access Control (ABAC) evaluates multiple factors before granting access. This can include the agent's trust score, the sensitivity of the requested data, the environment it's operating in, the specific tool or API being invoked, and the context of the task.
For example, an agent may be allowed to access a dataset in a sandbox environment but denied access in production unless additional conditions are met. This level of granularity ensures that access decisions are permission-based, context-aware and risk-aware.
Apply Strict Agent Lifecycle Management#
AI agents should be treated as fully managed identities. This involves implementing a structured lifecycle where agents must be registered before use, provisioned with controlled permissions, monitored during operation, and fully deprovisioned once their task is complete.
Credentials should also be rotated continuously, and any temporary identities should be torn down automatically to prevent lingering access.
Without lifecycle management, organizations risk accumulating orphaned agents, unused credentials, and hidden access paths that can be exploited later.
Enforce Zero Trust and Continuous Verification#
A single authentication event is not enough for AI agents. Their behavior can change rapidly, and their risk profile can evolve mid-execution.
Zero trust principles ensure that every action (including the initial login) is verified. These controls act as continuous guardrails, ensuring that even trusted agents are verified at every step rather than assumed safe after initial authentication.
If an agent deviates from its expected behavior—e.g., requesting unusual access, or interacting with new systems—controls should trigger immediately. This could involve restricting permissions, requiring additional validation, or terminating the session altogether.
Align Governance with Real-Time Execution#
Traditional governance models operate on scheduled reviews and periodic audits. That approach does not work for AI agents, which operate continuously and at high speed.
Governance must be embedded directly into execution. This means enforcing policies at the point of action, monitoring decisions as they happen, and adapting controls dynamically based on context.
Policy enforcement points (PEPs) and real-time decision engines become critical here, ensuring that every request is evaluated before it is allowed.
Maintain Full Traceability Across Agent Actions#
To govern effectively, you need to understand what actions were taken, and also why they were taken. This requires capturing detailed identity logs that link each action back to the originating request, the permissions granted, and the context in which the decision was made.
This level of traceability is essential for debugging issues, responding to incidents, and meeting compliance requirements.
How Zscaler automated access, accelerated onboarding, and simplified compliance with ConductorOne →
Read how Zscaler automated access, accelerated onboarding, and simplified compliance →
ConductorOne: The Platform Built for Agents That Make Their Own Access Decisions#

ConductorOne treats agents for what they are: dynamic, non-human identities that require real-time, policy-driven control. It gives organizations visibility into AI identity, access decisions, and execution behavior across systems.
Introducing AI Access Management →
ConductorOne also unifies identity governance across employees, service accounts, and AI agents. This ensures policies are consistent, enforcement is centralized, and nothing operates outside visibility.
And there's more. ConductorOne offers:
- Real-time, just-in-time access for AI agents: ConductorOne evaluates every access request as it happens, granting permissions only when needed and revoking them immediately after.
- Ephemeral credentials by design: Instead of relying on long-lived API keys or tokens, ConductorOne issues short-lived, context-aware credentials that expire automatically.
- Fine-grained, context-aware access control: Move past static roles. ConductorOne enforces attribute-based policies that consider real-time context before granting access.
- Full visibility into agent identity and activity: Every agent, every request, every action is tracked. ConductorOne provides a centralized view of non-human identities, including how access is requested, granted, and used across systems.
- Continuous verification and zero trust enforcement: ConductorOne continuously evaluates agent behavior and can revoke access immediately if something deviates from expected patterns.
Read how Ramp handles access control with ConductorOne →
The identity governance challenges agentic AI creates aren't problems organizations can solve by 'trying harder' with existing tools. Attempting to govern agents with quarterly access reviews, static RBAC, and point-in-time authentication is fundamentally inadequate.
Organizations need identity governance purpose-built for autonomous agents. And that's what ConductorOne provides.
Switch to ConductorOne. Before your agents operate faster than you can govern them.